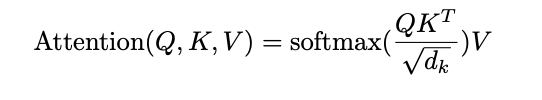Notes for “Attention is All You Need”
Transduction models: Basically models that take an input sequence and produce an output sequence. Both input and output sequence can be of varying lengths. Key points:
- Both of the input and output are a sequence.
- Models are mapping from one sequence space to another.
- Example: translation, summarisation, speech recognition, Question answering
- Example models: Seq2Seq models, Transformers, LSTM networks when used for sequence mapping
- Anti examples: Classification models, régression models,
So typically RNN works like this to process an input:
- Sequential processing in RNNs: They operate on one symbol at a time, in order. Each step produces a hidden state(ht) based on previous hidden state(h t-1) and current input.
- Alignment of positions with computation time: Each position in the sequence corresponds to a step in the computation. Model processes sequence in order from start to finish.
- Limitations on parallelisation: each step depends on previous one, not possible to process different parts of the sequence in parallel with a single example.
- Impact on efficiency: Limitation becomes problematic for long sequences. As sequence gets longer, time to process increases linearly.
Bottleneck in RNNs: Inability to parallelise within a sequence. Leads to:
- Slower training times
- Slower inference
- Difficulty with long range dependencies
Attention mechanism existed before this paper, but it was mostly used in addition to/as part of RNNs. But this paper proposed a new transformer architecture that basically relied mainly on attention mechanism. It allows for more parallelisation.
Background:
CNNs can do parallelisation and this has been used to optimise in case of models like Bytenet, ConvS2S. These models compete hidden representations in parallel for all input and output positions. This is in contrast to RNNs where everything happens in sequence.
Tradeoff: While these models allow for more parallelisation, they introduce a different challenge: number of operations required to relate signals from two arbitrary position grows as distance b/w these positions grow. Basically they trade off the computation problem of RNNs for a different problem - capturing the long-range dependencies efficiently.
TLDR: RNNs have parallelisation issue and CNNs have long range dependency issue. Transformers this is reduced to a constant number.
Self attention:
Self attention is a mechanism which allows a model to focus on different parts of the input sequence when processing each element of that same sequence. Also called intra attention. Contrast with traditional attention: Traditional attention works with two different sequences (I.e, machine translation, attention b/w source and target). Self attention operates within a single sequence.
TLDR: Self attention captures the spatial representation of the input sequence itself. CNNs also do that but in a different way. In CNN it’s sort of like a fixed-size, sliding scale, so the spatial relationship captured is sort of local. So its better for images, time series captures etc., Self attention captures this relationship regardless of distance, lets see in the next parts how.
End-to-End memory networks
These are neural networks designed to read from and write to a kind of external memory. Key features:
- They use attention mechanism to access this memory.
- They can be trained end-to-end meaning input to output without rewiring hand drawn intermediate steps.
- How they work?
- Input: They receive input
- Memory: They have “memory” component that stores information
- Attention: They use attention to find relevant information from the memory
- Output: They produce an output based on the input and retrieved memory.
- Difference from RNNs: RNNs process data sequentially. So no memory other than previously computed.
- Recurrent attention: They apply attention multiple times. This allows network to reason over multiple steps refining its understanding. Transformers do not use End to End networks, but they rely on attention mechanism to achieve this sort of thing.
Model architecture
In a traditional architecture of encoder-decoder: encoder maps an input sequence of symbols (x1, …. Xn) to a sequence of continuous representation z = (z1…. Zn). Given z decoder generated output (y1… yn) one at a time.
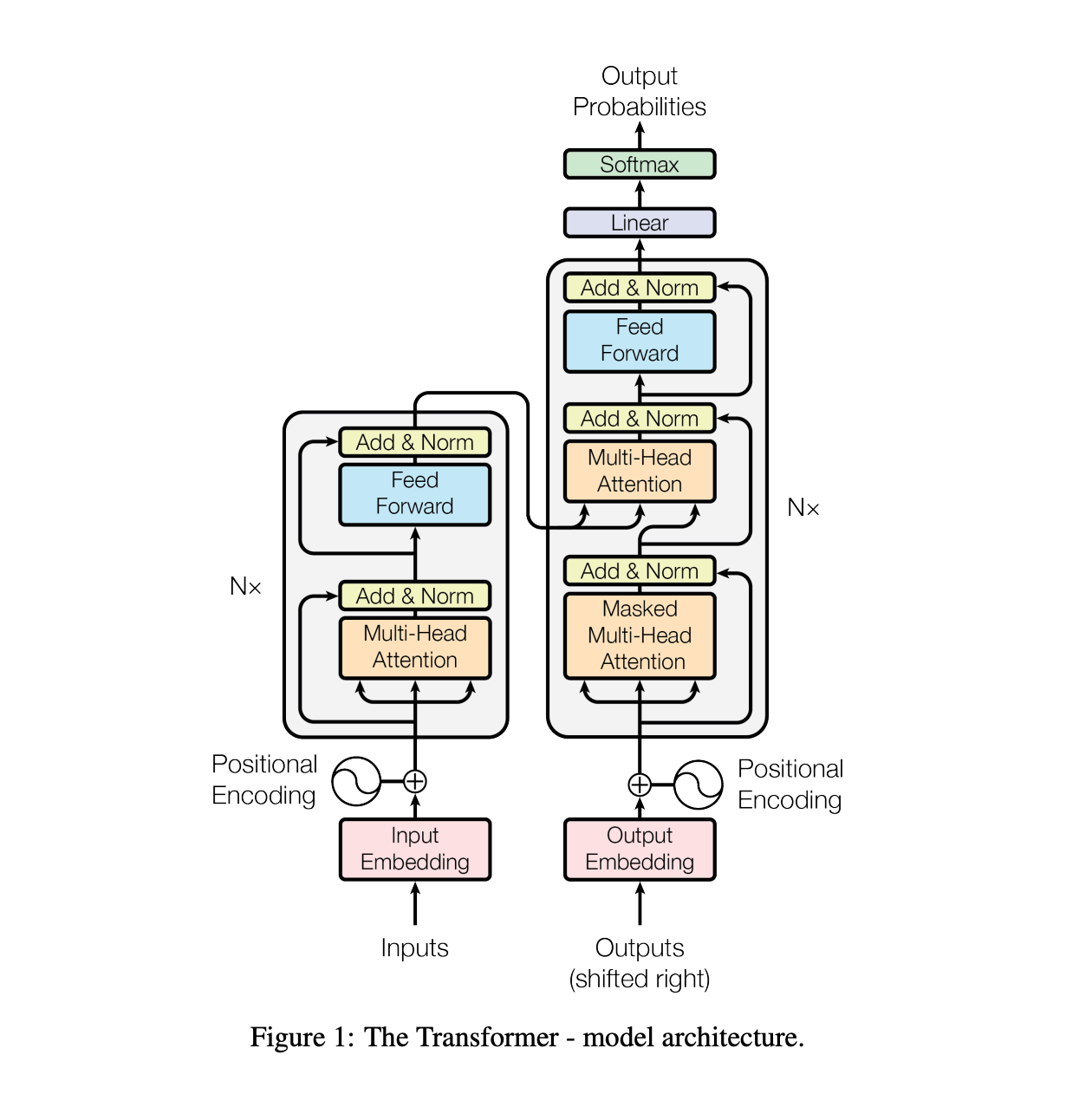
This is the architecture that the transformer follows using stacked self-attention and point-wise, fully connected layers for both encoder and decoder.
Autoregressive models:
Autoregressive means that the model generates output sequentially, using its own previous outputs as inputs for generating the next output.
In Transformer decoders:
- The decoder takes the encoder output and the previously generated tokens as input
- It uses self-attention to consider all previous outputs when generating the next token
Step-by-step example: Let’s say the model is generating a sentence:
- It generates the first word based on the input/context
- It generates the second word based on the input/context AND the first word it just generated
- It generates the third word based on the input/context AND the first two words it generated
- This process continues until the sequence is complete
Multi head self attention
Self attention: Allows the model to focus on different parts of the input sequence when processing each element. Each element can attend to other elements in the same sequence. Multi head: Instead of performing attention once. It’s performed in parallel. Multiple parallel attention operations.
How it works? Input is projected in three different representations: - Queries(Q) - Keys(K) - Values(V) Projection is done multiple times. Each head performs its own attention calculation. Results from all head are concatenated and linearly transformed.
Analogy: Imagine reading different parts of a sentences, different aspects of it(grammar, tone) and then combining all the aspects.
Masked multi head self attention
Basically the same multi head self attention but here we will have masked the input(at i) after i. This is basically to train the model to do next token prediction. During training the entire sequence is available but we will still mask the next tokens to ensure we do the training. During inference we allow the model to generate a token at a time. This is a decoder layer in transformers. Encoder needs to understand the full input so it uses multi head self attention, decoder needs to only see the previous outputs without peeking at future tokens. Encoder has another layer of multi head attention over encoder outputs after this.
Position-wise feed-forward network
It’s a simple layer applied to each position separately and identically. Components a) Two linear transformations b) A ReLU activation layer between them. This layer in there in both encoder and decode after the attention layer. Its basic functionality is to enhance the models ability to transform representation at each position. It complements the attention mechanism by adding another level of processing.
Residual connection
Residual connections also known as skip connections or shortcuts connections allow model to bypass one or more layers. Purpose: Helps in training very deep networks. It mitigates the vanishing gradient problem. It allows the model to access low level features. The output of each sub layer is added to its input .This sum becomes the input for next sublayer. Instead of passing the output of one layer to another, a skip connection added the input of a layer to its output. Basically it allows information to flow easily through the network.
Layer normalisation
This is a technique to normalise input across the features, typically applied to the activations of a layer. Applied after each layer after the residual connection layer. Layer norm unlike batch norm normalises across layers or features and not across batch.
⠀Important Takeaways: 1 The architecture is highly modular and repetitive. 2 It relies heavily on attention mechanisms, especially self-attention. 3 It uses techniques like residual connections and layer normalisation to facilitate training. 4 The decoder is designed to work autoregressively, generating one output at a time.
⠀This architecture allows the Transformer to process input sequences in parallel (unlike RNNs) while still capturing complex dependencies between different parts of the sequence. The multi-head attention mechanisms are key to its ability to focus on different aspects of the input simultaneously.
Encoder and decoder stacks
Let’s break down the key points to understand: 1 Overall Structure: * Both encoder and decoder consist of 6 identical layers stacked on top of each other. * This stacking allows the model to process information at different levels of abstraction. 2 Encoder Layer Components: a) Multi-head self-attention mechanism b) Position-wise feed-forward network * These components allow the model to capture complex relationships in the input. 3 Decoder Layer Components: a) Masked multi-head self-attention mechanism b) Multi-head attention over encoder output c) Position-wise feed-forward network * The additional attention layer allows the decoder to focus on relevant parts of the input when generating output. 4 Residual Connections: * Used around each sub-layer * Helps in training deep networks by allowing gradients to flow more easily 5 Layer Normalisation: * Applied after each sub-layer * Stabilises the learning process 6 Consistent Dimensionality: * All sub-layers and embedding layers produce outputs of dimension 512 * This consistency facilitates the residual connections 7 Masked Self-Attention in Decoder: * Prevents positions from attending to subsequent positions * Ensures the model doesn’t “look into the future” when generating sequences 8 Output Embedding Offset: * Decoder output embeddings are offset by one position * This, combined with masking, ensures the model’s autoregressive property
⠀Important Takeaways: 1 The architecture is highly modular and repetitive. 2 It relies heavily on attention mechanisms, especially self-attention. 3 It uses techniques like residual connections and layer normalisation to facilitate training. 4 The decoder is designed to work auto-regressively, generating one output at a time.
⠀This architecture allows the Transformer to process input sequences in parallel (unlike RNNs) while still capturing complex dependencies between different parts of the sequence. The multi-head attention mechanisms are key to its ability to focus on different aspects of the input simultaneously.
Attention
Basically attention is a transform mechanism to transform Query, Key and Values to output,
Components:
- Query(Q): A vector representing the current position or item we are focusing on
- Keys(K): A set of vectors representing all positions in the input
- Values(V): A set of vectors containing the actual content at each position
Process
- Compatibility: Calculate how well the query matches each key
- Weighting: Convert these compatibility scores into weights
- Aggregation: Use these weights to create a weighted sum of the values Basically for each input token which is a query, we define the attention calculation for other token which are the Keys we use the values and create a weighted sum of those values. This is done several times with multi head attention mechanism.
Note: There is a lot more details in the paper which I will visit later. For now this is the extent of the information I need to digest
Foundation of transformers.
This is the most important equation in the paper